
NCS5500 FIB Programming Speed
You can find more content related to NCS5500 including routing memory management, VRF, URPF, ACLs, Netflow following this link.
Programming Speed
In this post, we will measure the time it takes to learn routes in the RIB and in the FIB of an NCS 5500.
The first one exists in the Route Processor and will be provided by a BGP process.
The second one exists in multiple places, but to simplify the discussion, we will measure what is actually programmed in the NPU database.
We often hear that “Merchant Silicon systems program prefixes slowers than other products” but clearly this assertion is not based on facts and we will debunk it with this post and video.
Video demo
Let’s get started with a video we recorded and published on youtube.

In this demo, we advertised 1,200,000 IPv4 routes to our system under test:
- 300K IPv4/22
- 300K IPv4/23
- 600K IPv4/25
router bgp 1000
bgp_id 192.168.100.151
neighbor 192.168.100.200 remote-as 100
neighbor 192.168.100.200 update-source 192.168.100.151
capability ipv4 unicast
network 1 11.0.0.0/23 300000
nexthop 1 192.168.22.1
network 2 101.0.0.0/25 600000
nexthop 2 192.168.22.1
network 3 171.0.0.0/22 300000
nexthop 3 192.168.22.1
capability refresh
The results of this test were:
- RIB programming in RP: 133,000 pfx/s
- eTCAM programming speed: 29,000 pfx/s
For the next test in this blog post, we will use the exact same methodology but this time we will use a real internet view (recorded from a real internet router).
Test methodology
The system (DUT for Device Under Test) we will use for this demo is a chassis with a 36x 100G ports “Scale”. That means, it’s based on Jericho+ chipset with a new generation external TCAM. Since we are using IOS XR 6.3.2 or 6.5.1, all routes (IPv4 and IPv6) are stored on the eTCAM, regarless their prefix length.
RP/0/RP0/CPU0:TME-5508-1-6.5.1#sh plat 0/1
Node Type State Config state
--------------------------------------------------------------------------------
0/1/CPU0 NC55-36X100G-A-SE IOS XR RUN NSHUT
RP/0/RP0/CPU0:TME-5508-1-6.5.1#sh ver
Cisco IOS XR Software, Version 6.5.1
Copyright (c) 2013-2018 by Cisco Systems, Inc.
Build Information:
Built By : ahoang
Built On : Wed Aug 8 17:10:43 PDT 2018
Built Host : iox-ucs-025
Workspace : /auto/srcarchive17/prod/6.5.1/ncs5500/ws
Version : 6.5.1
Location : /opt/cisco/XR/packages/
cisco NCS-5500 () processor
System uptime is 1 day 1 hour 5 minutes
RP/0/RP0/CPU0:TME-5508-1-6.5.1#
The speed a router learns BGP routes is directly dependant on the neighbor and how fast it is able to advertise these prefixes. Since BGP is based on TCP, all messages are ack’d and the local process can request to slow down for any reason. That’s why we thought it woud not be relevant to use a route generator for this test. Or at least, we didn’t want the device under test to be directly peered to the route generator.
We decided to use an intermediate system of the same kind, for instance an NCS55A1-24H. This system will receive the BGP table from our route generator. When all the routes will be received in this intermediate system, we will enable the BGP session to the system under test.
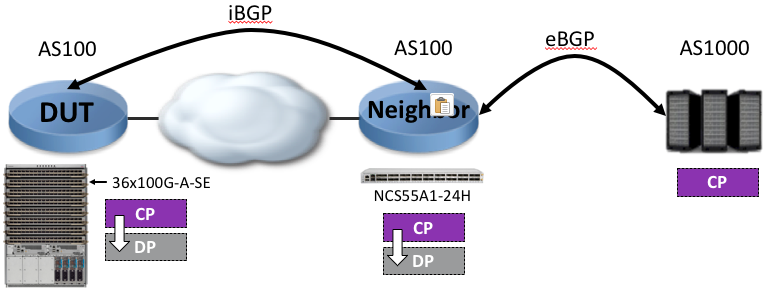
That way, the routes are advertised from a real router BGP stack and the results are representing what you could expect in your production environment.
We will monitor the programming speed of the entries in the RIB (in the Route Processor) and in the external TCAM (connected to the Jericho+ ASIC) via Streaming Telemetry.
The DUT will stream every second the counters related to the BGP table and the ASIC resource utilization:
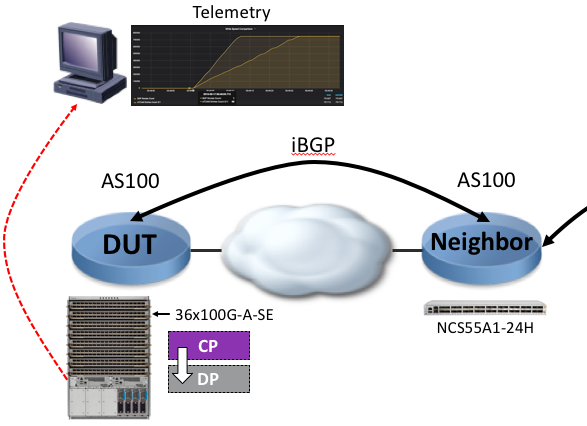
The related router configuration:
RP/0/RP0/CPU0:TME-5508-1-6.5.1#sh run telemetry model-driven
telemetry model-driven
destination-group DGroup1
address-family ipv4 10.30.110.40 port 5432
encoding self-describing-gpb
protocol tcp
!
!
sensor-group fib
sensor-path Cisco-IOS-XR-fib-common-oper:fib/nodes/node/protocols/protocol/vrfs/vrf/summary
!
sensor-group brcm
sensor-path Cisco-IOS-XR-fretta-bcm-dpa-hw-resources-oper:dpa/stats/nodes/node/hw-resources-datas/hw-resources-data
!
sensor-group routing
sensor-path Cisco-IOS-XR-ipv4-bgp-oper:bgp/instances/instance/instance-active/default-vrf/process-info
sensor-path Cisco-IOS-XR-ip-rib-ipv4-oper:rib/vrfs/vrf/afs/af/safs/saf/ip-rib-route-table-names/ip-rib-route-table-name/protocol/bgp/as/information
sensor-path Cisco-IOS-XR-ip-rib-ipv6-oper:ipv6-rib/vrfs/vrf/afs/af/safs/saf/ip-rib-route-table-names/ip-rib-route-table-name/protocol/bgp/as/information
!
subscription fib
sensor-group-id fib strict-timer
sensor-group-id fib sample-interval 1000
destination-id DGroup1
!
subscription brcm
sensor-group-id brcm strict-timer
sensor-group-id brcm sample-interval 1000
destination-id DGroup1
!
subscription routing
sensor-group-id routing strict-timer
sensor-group-id routing sample-interval 1000
destination-id DGroup1
!
!
RP/0/RP0/CPU0:TME-5508-1-6.5.1#
Step 0: “Before the test”
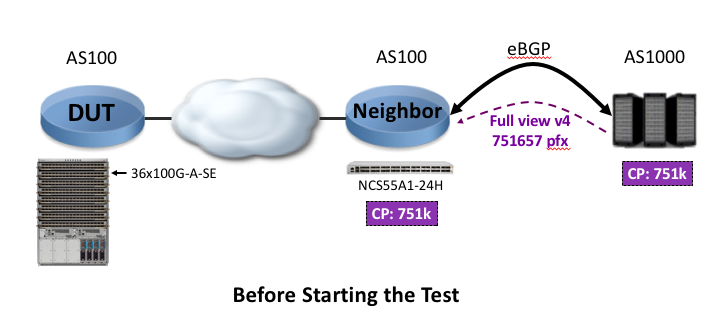
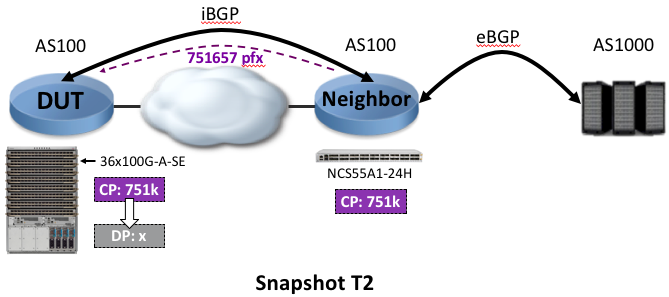
In this step, the router generator established an eBGP (AS1000 to AS100) session to the intermediate router and advertised the full internet view: 751,657 IPv4 routes.
We can check the routes are indeed received and valid but also their distribution in term of prefix length:
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2#sh bgp sum
BGP router identifier 1.1.1.22, local AS number 100
BGP generic scan interval 60 secs
Non-stop routing is enabled
BGP table state: Active
Table ID: 0xe0000000 RD version: 23817074
BGP main routing table version 23817074
BGP NSR Initial initsync version 1200006 (Reached)
BGP NSR/ISSU Sync-Group versions 0/0
BGP scan interval 60 secs
BGP is operating in STANDALONE mode.
Process RcvTblVer bRIB/RIB LabelVer ImportVer SendTblVer StandbyVer
Speaker 23817074 23817074 23817074 23817074 23817074 0
Neighbor Spk AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down St/PfxRcd
192.168.22.1 0 100 164033 15246 0 0 0 00:26:05 Idle (Admin)
192.168.100.151 0 1000 1241354 49602 23817074 0 0 00:05:14 751657
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2#sh dpa resources iproute loc 0/0/CPU0
"iproute" DPA Table (Id: 24, Scope: Global)
--------------------------------------------------
IPv4 Prefix len distribution
Prefix Actual Prefix Actual
/0 1 /1 0
/2 0 /3 0
/4 1 /5 0
/6 0 /7 0
/8 15 /9 13
/10 35 /11 106
/12 285 /13 550
/14 1066 /15 1880
/16 13419 /17 7773
/18 13636 /19 25026
/20 38261 /21 43073
/22 80751 /23 67073
/24 376982 /25 567
/26 2032 /27 4863
/28 15599 /29 16868
/30 41735 /31 52
/32 15
NPU ID: NPU-0 NPU-1
In Use: 751677 751677
Create Requests
Total: 12246542 12246542
Success: 12246542 12246542
... SNIP ...
You notice the session to the device under test (192.168.22.1) is currently in state “Idle (Admin)”.
It means the neighbor under the router bgp is configured with “shutdown”.
Step 1: Test begins at T1
The test begins when we unshut the BGP peer from the intermediate router.
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2#conf
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2(config)#
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2(config)#router bgp 100
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2(config-bgp)# neighbor 192.168.22.1
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2(config-bgp-nbr)#no shut
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2(config-bgp-nbr)#commit
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2(config-bgp-nbr)#end
RP/0/RP0/CPU0:NCS55A1-24H-6.3.2#
As soon as the session is established, the first routes are received and we note down this particular moment as “T1”:
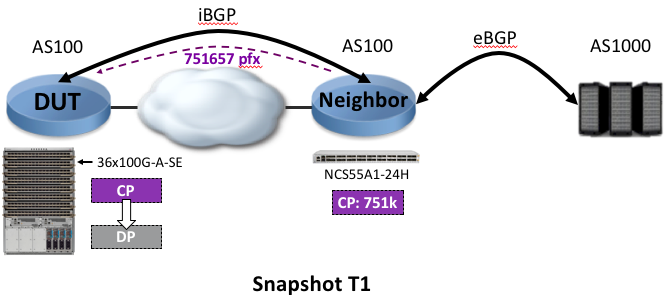
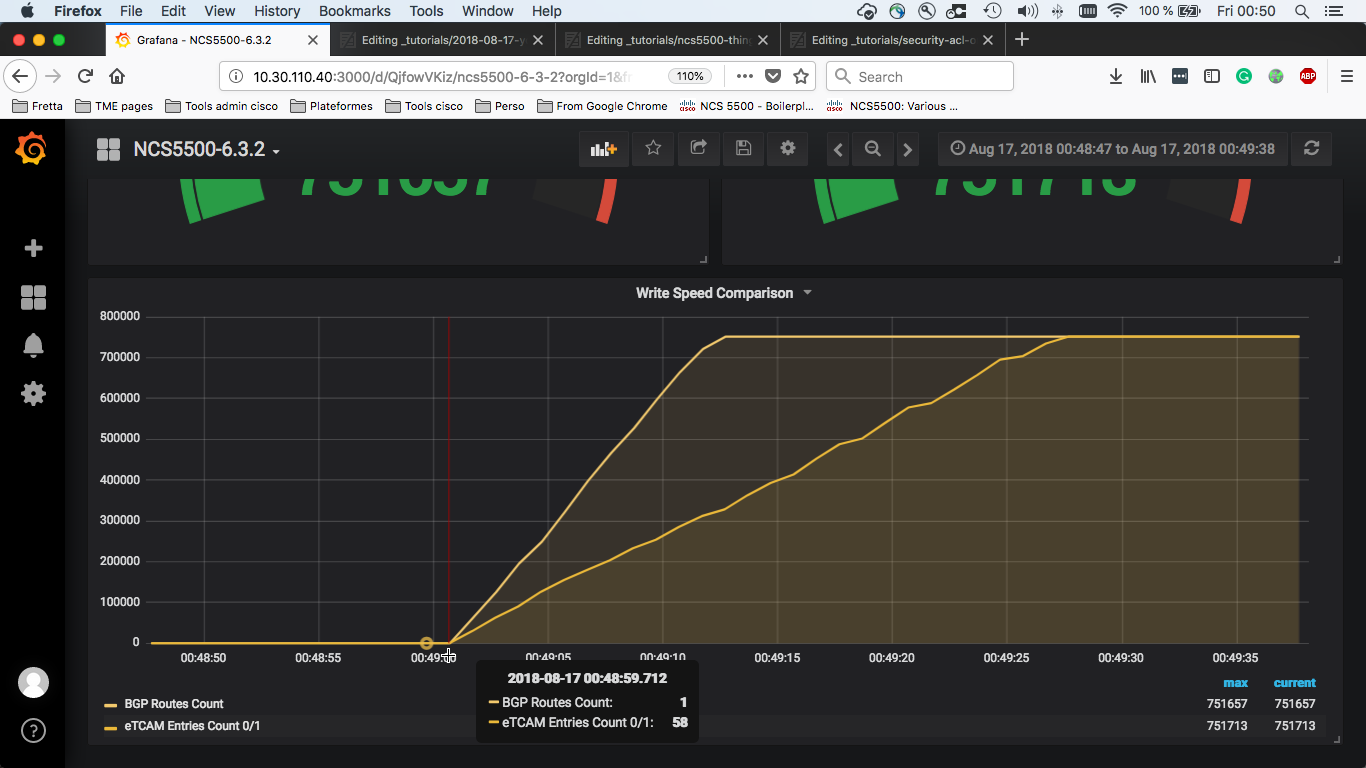
Step 2: All routes advertised via BGP at T2
We note down the T2 timestamp: it represents when all the BGP routes have been received on the Device Under Test.
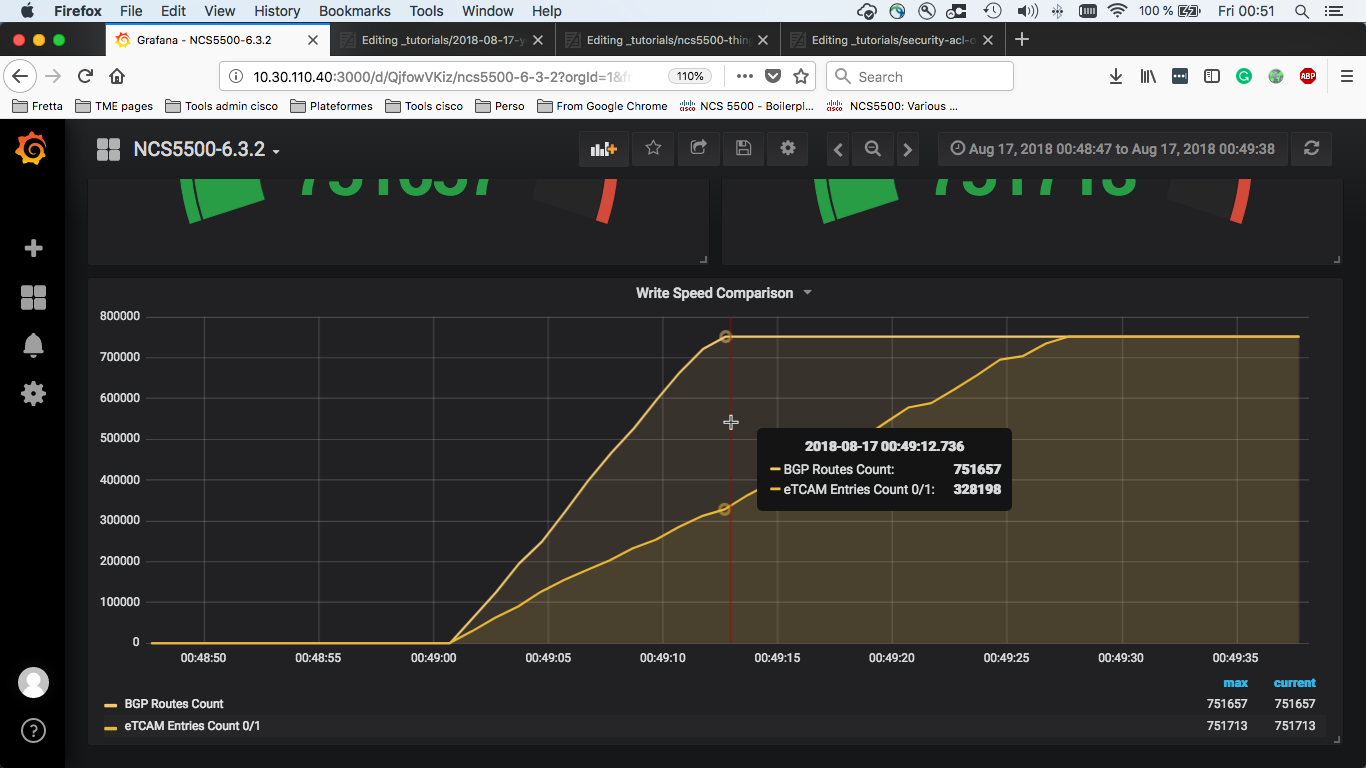
(T2 - T1) is the time it took to advertise all the BGP routes from intermediate router to DUT.
The speed to program the BGP in the RP RIB is 751677 / (T2 - T1) and is expressed in number of prefixes per second.
Step 3: All routes are programmed in eTCAM at T3
We note down the last timestamp: T3. It represents the moment all the prefixes have been programmed in the hardware.
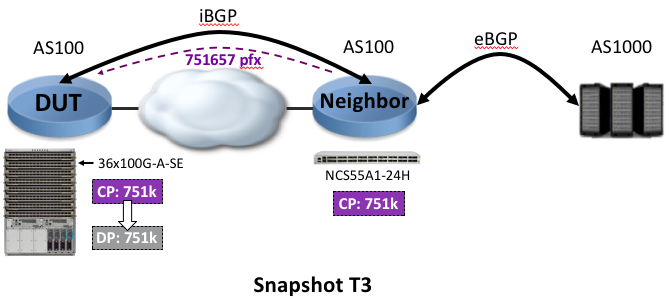
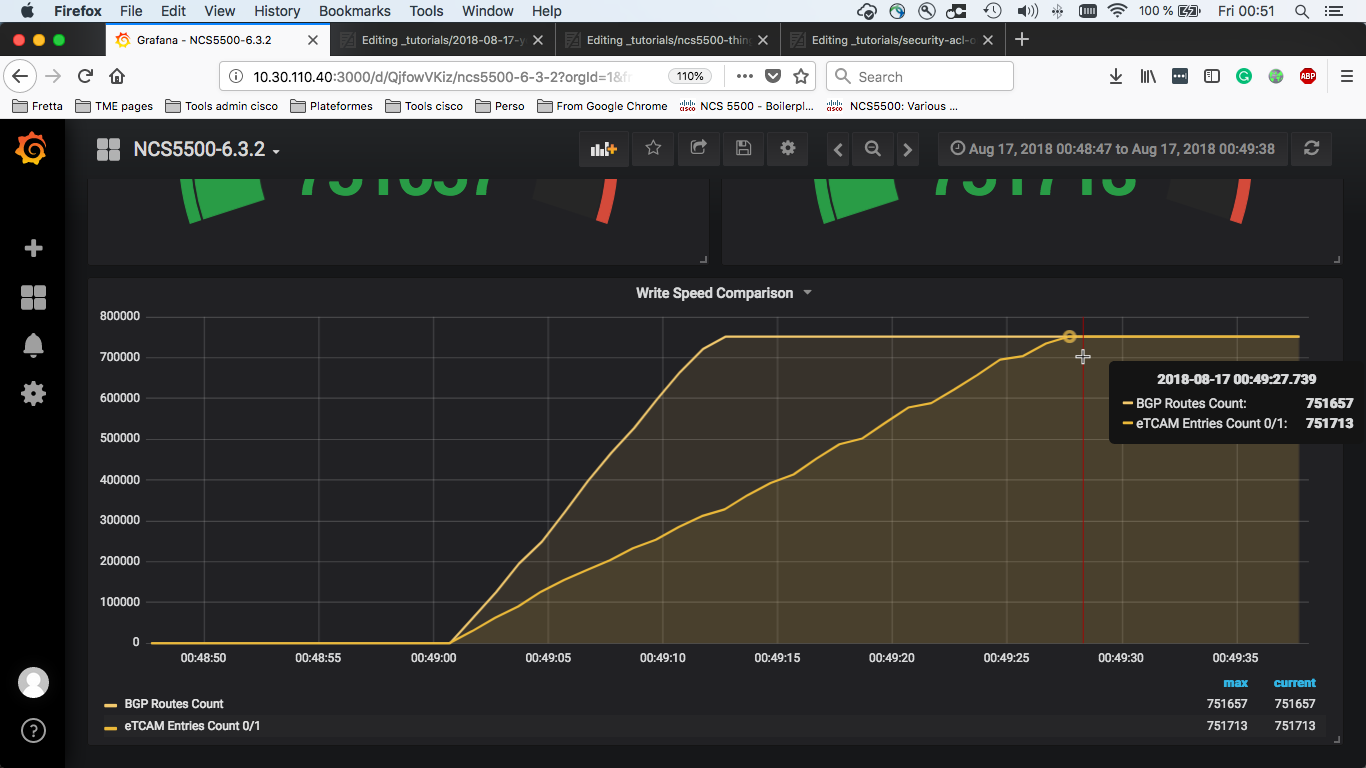
(T3 - T1) is the time it took to program all the routes in the Jericho+ external TCAM.
The speed to program the hardware is 751677 / (T3 - T1) and is expressed in number of prefixes per second.
Test results

(T2 - T1) = 49:12.736 - 48:59.712 = 12s
Speed to program BGP: 751,677 / 12 = 62,639 pfx/s
(T3 - T1) = 49:27.739 - 48:59.712 = 27s
Speed to program hardware: 751,677 / 27 = 27,839 pfx/s
With an internet distribution, we note that BGP advertisement is slower than the results we got in the first test with 1.2M routes (all aligned and sorted) but the hardware programming speed is consistent.
And we performed the opposite test with the shutdown of the BGP peer:

(T2 - T1) = 54:07.791 - 54:02.769 = 5s
Speed to withdraw all BGP routes: 751,677 / 5 = 150,335 pfx/s
(T3 - T1) = 54:25.760 - 54:02.769 = 23s
Speed to remove all routes from hardware: 751,677 / 23 = 32,681 pfx/s
Conclusion
The engineering team implemented multiple innovative ideas to speed up the process of programming entries in the hardware (prefix re-ordering, batching, direct memory access, etc).
The result is a programming performance comparable, if not better, to platforms based on custom silicon.
One last word, remember that we support multiple fast convergence features like BGP PIC Core. We maintain different databases for prefixes and for next-hop/adjacencies. It’s only necessary to change a pointer to a new next-hop when you lose a BGP peer, and not to reprogram the entire internet table.
Acknowledgements
Big shout out to Viktor Osipchuk for his help and availability. I invite you to check the excellent posts he published on MDT, Pipeline, etc: https://xrdocs.io/telemetry/.
Leave a Comment