
NCS5500 QoS Part 2 - Verifying Buffering in Lab and Live Networks
You can find more content related to NCS5500 including routing memory management, VRF, URPF, ACLs, Netflow following this link.
Also you can find the first part of this post here:
https://xrdocs.io/ncs5500/tutorials/ncs5500-qos-part-1-understanding-packet-buffering/
Checking Buffering in action
This second blog post will take concrete examples to illustrate the concepts covered in the first part.
The NCS5500 is based on a VOQ-only, single-lookup and ingress-buffering forwarding architecture.
We will use a lab example to illustrate how the system handles bursts, then we will present the monitoring tools / counters we can use to measure where packets are buffered, and finally we will present the data collected on 500+ NPUs in production.
This should answer frequently asked questions and clarify all potential doubts.
Video
We recommend to start watching this short Youtube video first:
https://www.youtube.com/watch?v=1qXD70_cLK8
Lab test
For this first part, and following customer request, we built a large test bed:
- NCS5508 with two line cards 36x100G-A-SE (each card is made of 4x NPU Jericho+, each one handling 9 ports 100G)
- 27 tester ports 100GE (Spirent) connected to 27 router ports
- 9 ports on LC 4 NPU 0
- 9 ports on LC 4 NPU 1
- 9 ports on LC 6 NPU 0
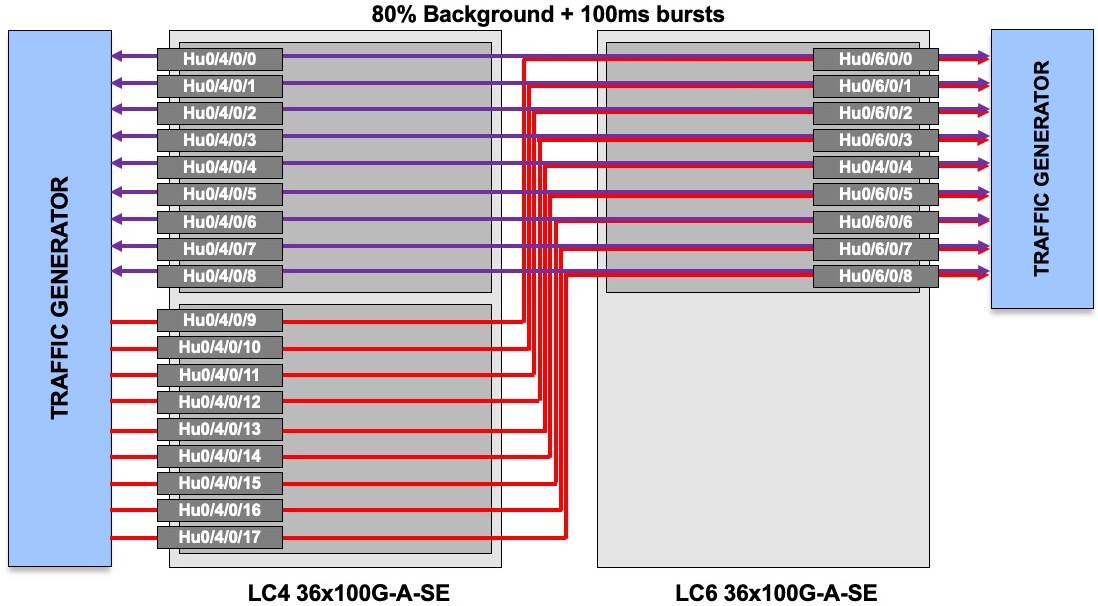
We generate a background / constant traffic of 80% line rate (80Gbps on each port) between two NPUs. This bi-directional traffic is displayed in purple in the diagram above.
Then, we will use the remaining 9 ports to generate peaks of traffic targeted to the ports Hu0/6/0/0-8 (shown in red in the diagram).
These bursts are lasting 100ms, every second.
On the tester, we didn’t make any specific PPM adjustment and used internal clock.
On the router, no specific configuration either. Interfaces are simply configured with IPv4 addresses (no QoS).
The tests performed are the following:
- test 1: 80% background and all the ports bursting at 20%. That means:
- 900ms at 80% LR
- 100ms at 100% LR
We verify no packets are dropped on the background or the bursts, and we also make sure with the counters that packets are exclusely handled in the OCB.
- test 2 :
- 80% background
- other ports bursting at 20%
- one single port bursts at 25%, creating a 5Gbps saturation for 100ms
Here again, we verify no packets are dropped on the background or the bursts, but also we verify that packets are sent to the DRAM.
It’s expected since one queue exceeds the threshold and is evicted to the external buffer.
This test is basic but has been requested by several customers to verify we had no drop in such situations. It proves it’s not the case, as designed.
Metrology
In the former test, we used specific counters to verify the buffering behavior.
Let’s review them.
We will collect the following Broadcom counters:
- IQM_EnqueuePktCnt: total number of packets handled by the NPU
- IDR_MMU_CREDITS: total number of packets moved to DRAM
- IQM_EnqueueDscrdPktCnt: total number of packets dropped because of taildrop
- IQM_RejectDramIneligiblePktCnt: total number of packets dropped because DRAM was not accessible in read, typically when the bandwidth to DRAM is saturated
- and potentially also IDR_FullDramRejectPktsCnt and IDR_PartialDramRejectPktsCnt
Form CLI “show controller npu stats counters-all instance all location all” we can extract: ENQUEUE_PKT_CNT, MMU_IDR_PACKET_COUNTER and ENQ_DISCARDED_PACKET_COUNTER
RP/0/RP0/CPU0:ROUTER#show controller npu stats counters-all instance all location all
FIA Statistics Rack: 0, Slot: 0, Asic instance: 0
Per Block Statistics:
Ingress:
NBI RX:
RX_TOTAL_BYTE_COUNTER = 161392268790033002
RX_TOTAL_PKT_COUNTER = 164628460653364
IRE:
CPU_PACKET_COUNTER = 0
NIF_PACKET_COUNTER = 164628460651867
OAMP_PACKET_COUNTER = 32771143
OLP_PACKET_COUNTER = 4787508
RCY_PACKET_COUNTER = 67452938
IRE_FDT_INTRFACE_CNT = 192
IDR:
MMU_IDR_PACKET_COUNTER = 697231761913
IDR_OCB_PACKET_COUNTER = 1
IQM:
ENQUEUE_PKT_CNT = 164640311902277
DEQUEUE_PKT_CNT = 164640311902198
DELETED_PKT_CNT = 0
ENQ_DISCARDED_PACKET_COUNTER = 90015441
To get the DRAM reject counters, we will use:
- show contr npu stats counters-all detail instance all location all
or if the IOS XR version doesn’t support the “detail” option, use the following instead: - show controllers fia diagshell 0 “diag counters” loc 0/x/CPU0
RP/0/RP0/CPU0:ROUTER#show contr npu stats counters-all detail instance all location all | i Dram
IDR FullDramRejectPktsCnt : 0
IDR FullDramRejectBytesCnt : 0
IDR PartialDramRejectPktsCnt : 0
IDR PartialDramRejectBytesCnt : 0
IQM0 RjctDramIneligiblePktCnt : 0
IQM1 RjctDramIneligiblePktCnt : 0
IDR FullDramRejectPktsCnt : 0
IDR FullDramRejectBytesCnt : 0
IDR PartialDramRejectPktsCnt : 0
IDR PartialDramRejectBytesCnt : 0
IQM0 RjctDramIneligiblePktCnt : 0
IQM1 RjctDramIneligiblePktCnt : 0
--%--SNIP--%--SNIP--%--
None of these counters are available through SNMP / MIB but instead you can use streaming telemetry:
You’ll found:
ENQUEUE_PKT_CNT: iqm-enqueue-pkt-cnt
leaf iqm-enqueue-pkt-cnt {
type uint64;
description "Counts enqueued packets";
MMU_IDR_PACKET_COUNTER: idr-mmu-if-cnt
leaf idr-mmu-if-cnt {
type uint64;
description "Performance counter of the MMU interface";
ENQ_DISCARDED_PACKET_COUNTER: iqm-enq-discarded-pkt-cnt
leaf iqm-enq-discarded-pkt-cnt {
type uint64;
description "Counts all packets discarded at the ENQ pipe";
At the moment (Apr 2019), RjctDramIneligiblePktCnt / FullDramRejectPktsCnt / PartialDramRejectPktsCnt are not available in the data models and therefor, can’t be streamed.
Auditing real production routers
We have the counters available and we asked multiple customers (25+) to collect data from their production routers.
In total, we had information for 550 NPUs transporting live traffic in multiple network positions:
- IP core
- MPLS core (P/LSR)
- Internet border (transit / peering)
- CDN (connected to FB, Akamai, Google Cache, Netflix, …)
- PE (L2VPN and L3VPN)
- Aggregation
- SPDC / ToR leaf
The data aggregated is helpful since it gives a vision of what is happening in reality.
The total amount of traffic measured is tremendous: 24,526,679,839,376,100 packets!!!
Not in lab, not in academic models / simulations, but in real routers.
With the show commands described in former section, we extracted:
- ENQUEUE_PKT_CNT: packets transmitted in the NPU
- MMU_IDR_PACKET_COUNTER: packets passed to DRAM
- ENQ_DISCARDED_PACKET_COUNTER: packets taildropped
- RjctDramIneligiblePktCnt: packets drop because of DRAM bandwidth
Dividing MMU_IDR_PACKET_COUNTER by ENQUEUE_PKT_CNT, we can compute the ratio of packets moved to DRAM.
–> 0,151%
This number is an average value and should be considered as such. It shows that indeed, the vast majority of the traffic is handled in OCB (inside the NPU).
Dividing ENQ_DISCARDED_PACKET_COUNTER by ENQUEUE_PKT_CNT, we can compute the ratio of packets taildropped.
–> 0,0358%
Having drops is normal in the life of a router. Multiple reasons here, from TCP windowing to temporary congestion situations.
Finally, RjctDramIneligiblePktCnt will tell us if the link from the NPU to the DRAM can get saturated and drops packets with production traffic.
–> not a single packet discarded in such scenario.
LAPTOP: nicolas$ grep RjctDramIneligiblePktCnt * | wc -l
1570
LAPTOP: nicolas$ grep RjctDramIneligiblePktCnt * | grep " 0" | wc -l
1570
LAPTOP: nicolas$ grep RjctDramIneligiblePktCnt * | grep -v " 0" | wc -l
0
LAPTOP: nicolas$
In this chart, we sort by numbers of ENQUEUE_PKT_CNT: it represents the most active ASICs in term of packets handled.
| Rank | ENQUEUE_PKT_CNT | MMU_IDR | ENQ_DISC | RjctDram | Ratio DRAM % | Ratio drops % | Network roles |
|---|---|---|---|---|---|---|---|
| 1 | 527 787 533 239 280 | 7 369 339 005 | 1 705 600 246 | 0 | 0,001396 | 0,000323 | IP Core |
| 2 | 527 731 939 299 538 | 7 637 629 256 | 1 692 666 188 | 0 | 0,001447 | 0,000321 | IP Core |
| 3 | 392 487 675 531 358 | 111 916 953 940 | 24 771 334 182 | 0 | 0,028515 | 0,006311 | Peering |
| 4 | 348 026 620 119 625 | 1 610 856 619 | 781 841 479 | 0 | 0,000463 | 0,000225 | IP Core |
| 5 | 342 309 183 713 774 | 1 348 042 248 | 855 820 846 | 0 | 0,000394 | 0,000250 | IP Core |
| 6 | 327 474 089 745 397 | 906 227 869 | 871 575 599 | 0 | 0,000277 | 0,000266 | IP Core |
| 7 | 312 691 087 570 935 | 149 450 319 | 13 211 540 367 | 0 | 0,000048 | 0,004225 | Peering |
| 8 | 309 754 368 573 783 | 217 802 498 | 7 194 870 813 | 0 | 0,000070 | 0,002323 | Peering |
| 9 | 286 534 007 041 471 | 7 937 852 208 | 208 639 446 202 | 0 | 0,002770 | 0,072815 | IP Core |
| 10 | 285 891 289 921 804 | 17 316 635 372 | 208 339 055 090 | 0 | 0,006057 | 0,072874 | IP Core |
| 11 | 282 857 716 700 675 | 4 619 576 899 | 213 929 762 107 | 0 | 0,001633 | 0,075632 | IP Core |
| 12 | 281 159 664 612 018 | 13 756 617 725 | 448 617 960 | 0 | 0,004893 | 0,000160 | MPLS Core |
| 13 | 263 035 976 927 915 | 6 226 947 181 | 191 620 663 098 | 0 | 0,002367 | 0,072850 | IP Core |
| 14 | 253 469 417 751 706 | 4 811 103 101 | 1 078 118 413 | 0 | 0,001898 | 0,000425 | IP Core |
| 15 | 253 388 455 606 099 | 4 808 169 387 | 1 080 970 708 | 0 | 0,001898 | 0,000427 | IP Core |
| 16 | 249 198 998 283 888 | 723 211 883 | 432 154 974 | 0 | 0,000290 | 0,000173 | IP Core |
| 17 | 245 552 977 886 019 | 1 672 035 279 | 1 336 139 650 | 0 | 0,000681 | 0,000544 | IP Core |
| 18 | 244 787 789 764 429 | 1 422 882 240 | 1 211 167 690 | 0 | 0,000581 | 0,000495 | IP Core |
| 19 | 244 639 576 497 565 | 1 347 623 535 | 1 122 306 072 | 0 | 0,000551 | 0,000459 | IP Core |
| 20 | 244 604 586 809 869 | 1 935 267 429 | 1 384 016 976 | 0 | 0,000791 | 0,000566 | IP Core |
| 21 | 243 908 249 497 111 | 586 491 218 | 410 239 247 | 0 | 0,000240 | 0,000168 | IP Core |
| 22 | 243 639 692 775 431 | 17 237 153 490 | 1 434 003 860 | 0 | 0,007075 | 0,000589 | Peering |
| 23 | 237 152 936 875 785 | 448 662 754 | 384 071 603 | 0 | 0,000189 | 0,000162 | IP Core |
| 24 | 224 477 013 789 647 | 13 369 954 892 | 1 319 318 749 | 0 | 0,005956 | 0,000588 | MPLS Core |
| 25 | 219 820 911 786 839 | 1 068 821 932 | 647 226 846 | 0 | 0,000486 | 0,000294 | IP Core |
| 26 | 205 119 650 216 462 | 766 453 141 | 568 411 772 | 0 | 0,000374 | 0,000277 | IP Core |
| 27 | 203 306 915 869 451 | 61 364 621 713 | 12 422 238 060 | 0 | 0,030183 | 0,006110 | Peering |
| 28 | 194 981 015 445 738 | 19 793 539 645 | 117 282 213 | 0 | 0,010152 | 0,000060 | MPLS Core |
| 29 | 182 104 629 921 870 | 163 108 290 | 12 704 233 685 | 0 | 0,000090 | 0,006976 | Peering |
| 30 | 180 871 118 289 426 | 1 362 976 328 269 | 38 037 126 715 | 0 | 0,753562 | 0,021030 | P+PE |
| 31 | 173 166 873 157 959 | 397 471 140 | 353 417 929 | 0 | 0,000230 | 0,000204 | IP Core |
| 32 | 167 311 796 856 352 | 1 282 666 496 069 | 36 120 954 409 | 0 | 0,766632 | 0,021589 | P+PE |
| 33 | 164 640 767 868 235 | 697 231 782 299 | 90 015 446 | 0 | 0,423487 | 0,000055 | CDN |
| 34 | 164 640 311 902 277 | 697 231 761 913 | 90 015 441 | 0 | 0,423488 | 0,000055 | CDN |
| 35 | 160 506 138 361 929 | 851 487 161 | 1 826 760 067 | 0 | 0,000531 | 0,001138 | IP Core |
| 36 | 158 521 030 661 438 | 1 391 033 571 161 | 3 987 222 205 | 0 | 0,877507 | 0,002515 | CDN |
| 37 | 157 286 154 450 629 | 14 699 938 426 | 44 060 250 | 0 | 0,009346 | 0,000028 | Peering |
| 38 | 154 081 895 058 387 | 623 038 967 | 483 267 224 | 0 | 0,000404 | 0,000314 | IP Core |
| 39 | 143 902 175 998 205 | 205 944 615 947 | 595 151 004 | 0 | 0,143114 | 0,000414 | Peering |
| 40 | 143 686 937 442 122 | 12 638 644 | 130 005 734 | 0 | 0,000009 | 0,000090 | Peering |
| 41 | 142 498 738 296 176 | 649 883 065 | 1 404 348 505 | 0 | 0,000456 | 0,000986 | IP Core |
| 42 | 142 426 983 443 239 | 645 597 568 | 1 417 441 644 | 0 | 0,000453 | 0,000995 | IP Core |
| 43 | 138 083 165 878 093 | 2 778 355 335 | 54 030 686 | 0 | 0,002012 | 0,000039 | Peering |
| 44 | 130 425 299 235 308 | 235 149 102 989 | 117 322 562 | 0 | 0,180294 | 0,000090 | CDN |
| 45 | 125 379 522 379 915 | 219 241 802 484 | 77 781 184 | 0 | 0,174863 | 0,000062 | CDN |
| 46 | 122 178 283 814 177 | 122 250 106 | 2 168 387 244 | 0 | 0,000100 | 0,001775 | Peering |
| 47 | 121 842 623 410 092 | 419 677 747 284 | 419 677 747 284 | 0 | 0,344442 | 0,344442 | P+Peering |
| 48 | 121 842 227 567 846 | 419 677 746 356 | 419 677 746 356 | 0 | 0,344444 | 0,344444 | P+Peering |
| 49 | 119 048 492 308 148 | 19 756 851 882 | 1 468 594 303 | 0 | 0,016596 | 0,001234 | Peering |
| 50 | 118 902 447 078 432 | 20 140 676 286 | 1 437 569 523 | 0 | 0,016939 | 0,001209 | Peering |
For the most busiest NPUs collected, we see the DRAM ratio and taildrop ratio being actually much smaller than aggregated numbers.
How to read these numbers?
First of all, it demonstrates clearly that most of the packets are handled inside the ASIC, only a very small portion of the traffic being evicted to DRAM.
Second, with RjctDramIneligiblePktCnt being zero in EVERY data collection, we prove that bandwidth from NPU to DRAM (900Gbps unidirectional) is correctly dimensionned. It handles the real burstiness of the traffic without a single drop.
Last, the data collected represents a snapshot. It is recommended to collect these counters regularly and to analyze them with the network activity during the interval.
Having higher numbers in your network may be correlated to a particular outage or specific situation.
Having small numbers, in the other hand, is much easier to read (no drops being… no drops).
Conclusion
In conclusion, the ingress-buffering / VOQ-only model is well adapted for real networks.
We have seen “academic” studies trying to prove the contrary, but the numbers are talking here.
A sandbox, or an imaginary model are not relevant approach.
Production networks deployed all around the world, in different positions/roles, transporting Petabytes of traffic for multiple years, prove the efficiency of this architecture.
Leave a Comment