
Using Pipeline: Integrating with InfluxDB
Using Pipeline
In an earlier blog, I discussed how to configure Pipeline to write Model-Driven-Telemetry (MDT) data to a plain text file. In this tutorial, I’ll describe the Pipeline configuration that enables you to write telemetry data into InfluxDB, an open source platform for time-series data.
Here’s a picture of what we are trying to do: 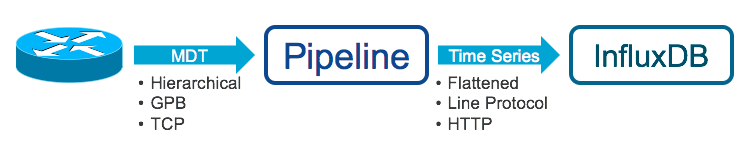
Pipeline and InfluxDB can run on the same server or on different servers, as long as there is connectivity between them.
Preparing the Router
This tutorial assumes that you’ve already configured your router for model-driven telemetry (MDT) with TCP dial-out using the instructions in this tutorial. The IP address and port that you specify in the destination-group in the router config should match the IP address and port on which Pipeline is listening.
Getting Influxdb
This tutorial assumes that you have a working instance of InfluxDB with an IP address that is accessible from your Pipeline instance and has a database named “mdt_db”. If you want to use a different database name, edit the pipeline.conf output stage configuration below.
InfluxDB is available from github and includes documentation on creating databases. InfluxDB is also available as a Docker container.
Getting Pipeline
Pipeline is available from github.
Pipeline.conf
Configuring the Input Stage for TCP Dial-Out
For this tutorial, I’ll use the default pipeline.conf input stage for MDT TCP Dial-Out described in the TCP to Textfile tutorial. If you take out all the comments, this reduces to 5 lines in pipeline.conf:
[testbed]
stage = xport_input
type = tcp
encap = st
listen = :5432
This [testbed] section shown above will work “as is” for MDT with TCP dial-out. If you want to change the port that Pipeline listens on to something other than “5432”, you can edit this section of the pipeline.conf. Otherwise, we’re good to go for the input stage.
Configuring the Output Stage for InfluxDB
To push the data to InfluxDB, we need a “metrics” output stage in Pipeline. The default pipeline.conf file comes with an example metrics stage section called [mymetrics]. Taking out the comments, the important lines are as follows:
[mymetrics]
stage = xport_output
type = metrics
file = metrics.json
dump = metricsdump.txt
output = influx
influx = http://10.152.176.74:8086
database = mdt_db
This configuration instructs Pipeline to post MDT data to an InfluxDB instance at 10.152.176.74:8086 that has a database named mdt_db.
Before posting the data to influxdb, pipeline transforms the data according to the instructions in the metrics.json file. More on this in the next section.
Finally, the dump = metricsdump.txt option lets you locally dump a copy of the same data that is being pushed to influxdb. This is useful for first-time setup and debugging.
Using metrics.json
TL;DR If you are using the sensor-path from the TCP to Textfile tutorial and the default metrics.json, you actually have nothing to do. But if you have a burning desire to know how things works, please read the rest of the section!
YANG models define data hierarchies. Because MDT is based on YANG models, the raw telemetry data from a router is also hierarchical. Time-series databases, however, typically expect data in a simple format: metric name, metric value, timestamp and, optionally, some tags or keys. In influxdb, this format is called the “Line Protocol.”
One of the important functions of Pipeline is to take the hierarchical YANG-based data and transform it into the Line Protocol for easy consumption by influxdb. Pipeline takes the complex, hierarchical YANG-modeled data and flattens it into multiple time series. Pipeline uses the metrics.json file to perform the transformation. The metrics.json file contains a series of json objects, one for each YANG model and sub-tree path that the router streams.
Take the sensor-path configured on the router in the TCP Dial Out Tutorial: Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters. The corresponding object in the default metrics.json is below:
{
"basepath" : "Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters",
"spec" : {
"fields" : [
{"name" : "interface-name", "tag" : true},
{"name" : "packets-received"},
{"name" : "bytes-received"},
{"name" : "packets-sent"},
{"name" : "bytes-sent"},
{"name" : "output-drops"},
{"name" : "output-queue-drops"},
{"name" : "input-drops"},
{"name" : "input-queue-drops"},
{"name" : "input-errors"},
{"name" : "crc-errors"},
{"name" : "input-ignored-packets"},
{"name" : "output-errors"},
{"name" : "output-buffer-failures"},
{"name" : "carrier-transitions"}
]
}
}
This entry in the metrics.json file enables Pipeline to post interface statistics in the influxdb Line Protocol with the following characteristics:
Measurement:
- Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters
Tag Names and Values
- EncodingPath=Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counter
- Producer=SunC
- interface-name=MgmtEth0/RP0/CPU0/0
Field Keys and Values
- bytes-received=307428735
- bytes-sent=23017070265
-
Timestamp
- 1491942788950000000
You might have noticed that “interface-name” is one of the Tag Names, not a Field Key above. There are two ways to get an MDT metric marked as a Tag. First, recall that the router sends MDT data as one of two types: Keys and Content. Pipeline will automatically translate items in the MDT Keys section to a Tag. You can also use the metrics.json file. Any entry in the metrics.json file with "tag" : true will be added to the Tag Names in the Line Protocol and not sent as a Field Key.
Also good to know: if you don’t have an entry in the metrics.json file, then that data point will not be posted to InfluxDB, even if the router sends that data to Pipeline. That’s actually a feature! Because bulk data collection is more efficient for the router, the router streams data at the container level of the YANG model. That means you will sometimes receive more data than you actually need. Pipeline gives you the ability to filter what data gets passed on to your time series database.
Final takeaway, if the path you are streaming is already described in the metrics.json and has all the fields you care about (as is this case here), there is nothing to do. Adding objects to the metrics.json will be the topic of a future tutorial.
Running Pipeline
Run pipeline as usual, by executing the binary in the bin directory. Pipeline will use the pipeline.conf file by default. Pipeline will prompt you for credentials to use when posting to influxdb.
scadora@darcy:~/bigmuddy-network-telemetry-pipeline$ bin/pipeline
Startup pipeline
Load config from [pipeline.conf], logging in [pipeline.log]
CRYPT Client [mymetrics],[http://10.152.176.84:8086]
Enter username: admin
Enter password:
Wait for ^C to shutdown
Power users will appreciate the -log= -debug option for pipeline:
scadora@darcy:~/bigmuddy-network-telemetry-pipeline$ bin/pipeline -log= -debug
INFO[2017-04-12 14:41:05.038501] Conductor says hello, loading config config=pipeline.conf debug=true fluentd= logfile= maxthreads=1 tag=pipeline version="v1.0.0(bigmuddy)"
DEBU[2017-04-12 14:41:05.039562] Conductor processing section... name=conductor section=inspector tag=pipeline
DEBU[2017-04-12 14:41:05.039690] Conductor processing section, type... name=conductor section=inspector tag=pipeline type=tap
INFO[2017-04-12 14:41:05.039800] Conductor starting up section name=conductor section=inspector stage="xport_output" tag=pipeline
DEBU[2017-04-12 14:41:05.039887] Conductor processing section... name=conductor section=mymetrics tag=pipeline
DEBU[2017-04-12 14:41:05.039940] Conductor processing section, type... name=conductor section=mymetrics tag=pipeline type=metrics
INFO[2017-04-12 14:41:05.039982] Conductor starting up section name=conductor section=mymetrics stage="xport_output" tag=pipeline
<output snipped for brevity>
Seeing the Data Before It Goes To InfluxDB
Since we configure a “dump” file in the [mymetrics] output stage above, Pipeline will dump a local copy of the data it posts to InfluxDB into a text file in the Line Protocol format. This is a good way to confirm that Pipeline is receiving data from the router and parsing it with a valid metrics.json entry.
scadora@darcy:~/bigmuddy-network-telemetry-pipeline$ tail -f metricsdump.txt_wkid0
Server: [http://10.152.176.84:8086], wkid 0, writing 7 points in db: mdt_db
(prec: [ms], consistency: [], retention: [])
Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters,EncodingPath=Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters,Producer=SunC,interface-name=Bundle-Ether1 bytes-received=175069849,bytes-sent=9057828,carrier-transitions=0i,crc-errors=0i,input-drops=0i,input-errors=0i,input-ignored-packets=0i,input-queue-drops=0i,output-buffer-failures=0i,output-drops=0i,output-errors=0i,output-queue-drops=0i,packets-received=1189543,packets-sent=103020 1491943978355000000
Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters,EncodingPath=Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters,Producer=SunC,interface-name=Null0 bytes-received=0,bytes-sent=0,carrier-transitions=0i,crc-errors=0i,input-drops=0i,input-errors=0i,input-ignored-packets=0i,input-queue-drops=0i,output-buffer-failures=0i,output-drops=0i,output-errors=0i,output-queue-drops=0i,packets-received=0,packets-sent=0 1491943978355000000
Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters,EncodingPath=Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters,Producer=SunC,interface-name=MgmtEth0/RP0/CPU0/0 bytes-received=307431285,bytes-sent=23017071885,carrier-transitions=1i,crc-errors=0i,input-drops=139i,input-errors=0i,input-ignored-packets=0i,input-queue-drops=0i,output-buffer-failures=0i,output-drops=0i,output-errors=0i,output-queue-drops=0i,packets-received=4338703,packets-sent=16808000 1491943978355000000
InfluxDB
To validate that the data has been received by influxdb, you can use curl to query the database:
$ curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mdt_db" --data-urlencode "q=SELECT \"bytes-sent\" FROM \"Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters\" WHERE \"interface-name\"='GigabitEthernet0/0/0/0'"
{
"results": [
{
"series": [
{
"name": "Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters",
"columns": [
"time",
"bytes-sent"
],
"values": [
[
"2017-04-11T21:04:57.205Z",
1.911903356e+09
],
[
"2017-04-11T21:05:27.214Z",
1.911903356e+09
],
[
"2017-04-11T21:05:57.226Z",
1.911911181e+09
]
]
}
]
}
]
}
If you are using grafana to query and visualize your influxdb data, you can use all the queries and dashboards you know and love, as in this simple graph of packets sent on Gigabit Ethernet 0/0/0/0:
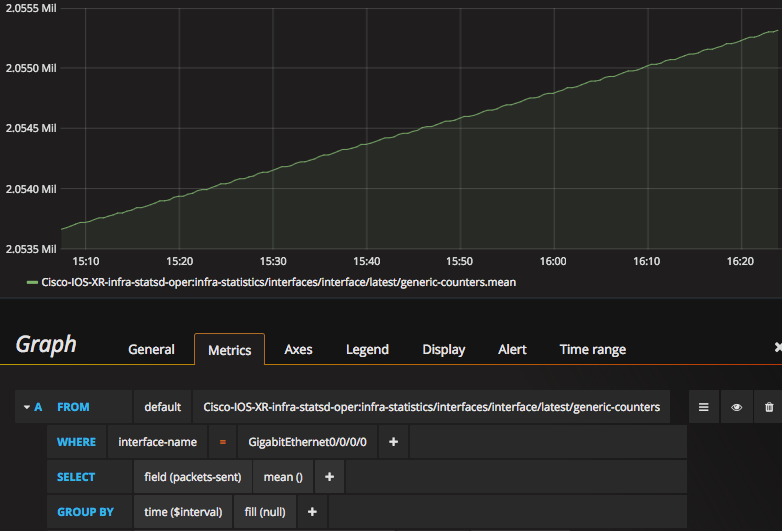
For those hearty souls who slogged through the Using metrics.json section, note that we could use interface-name in the Where clause of the query above because it was sent as a Tag in the Line Protocol.
Conclusion
Pipeline gives you a easy, flexible way to get data into commonly used open-source tools like influxdb. Give it a try and let us know what you think!
Leave a Comment